

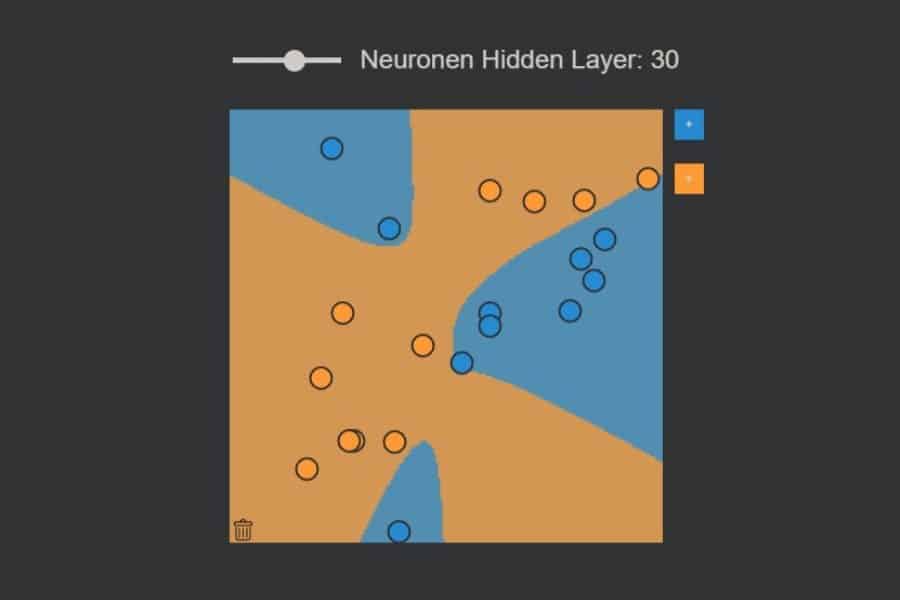
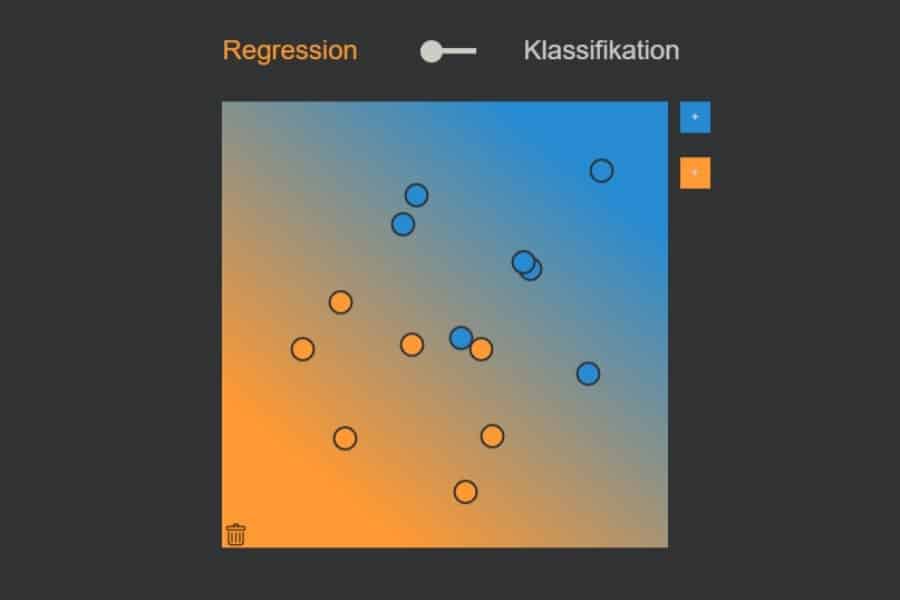
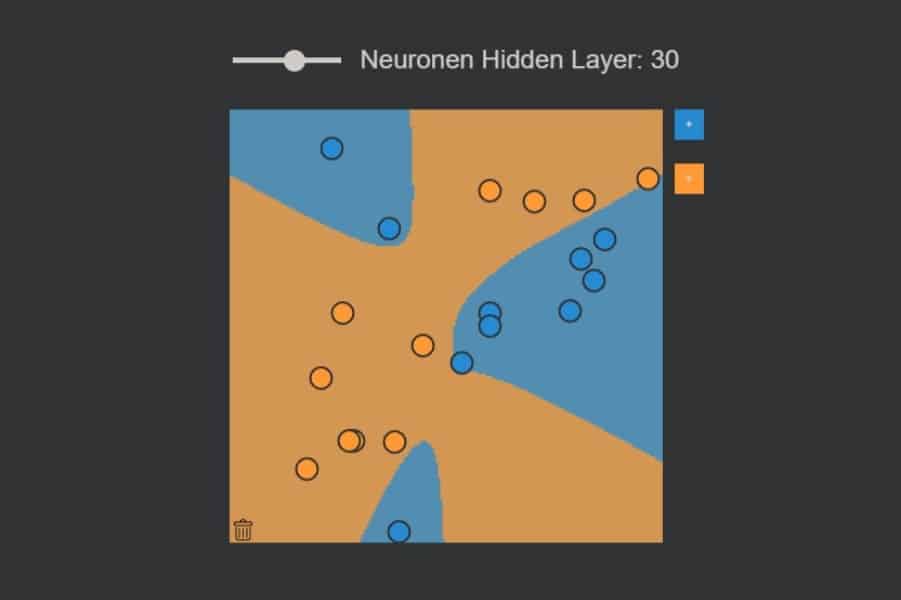
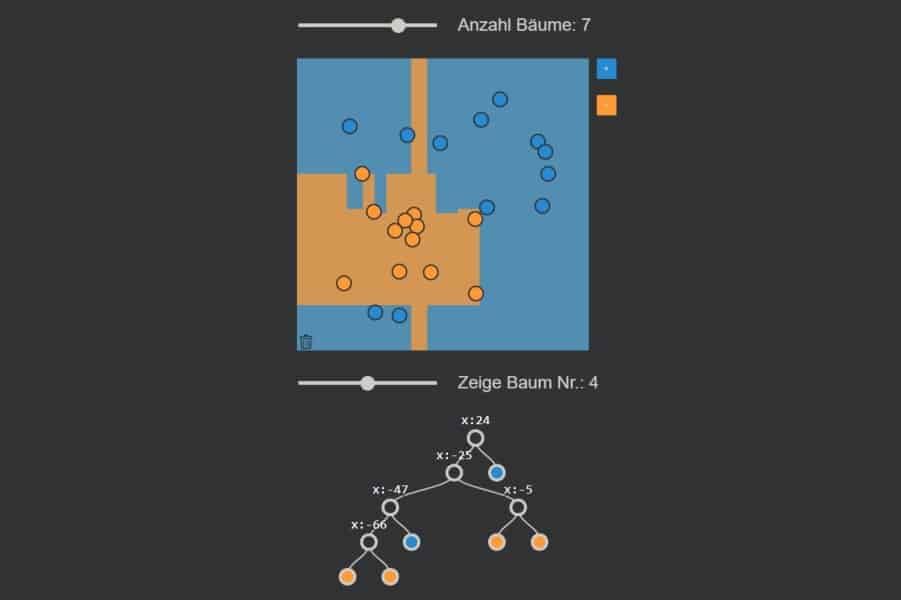
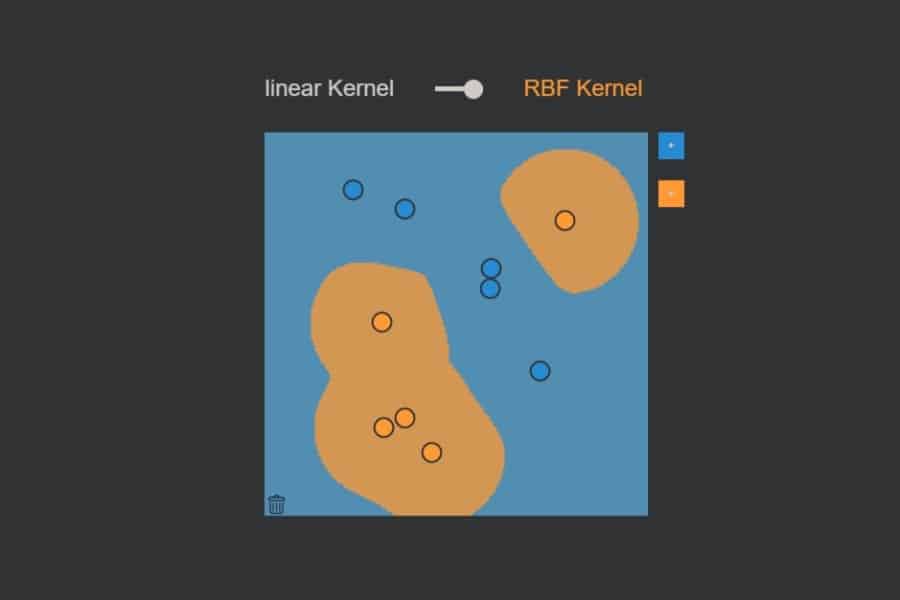
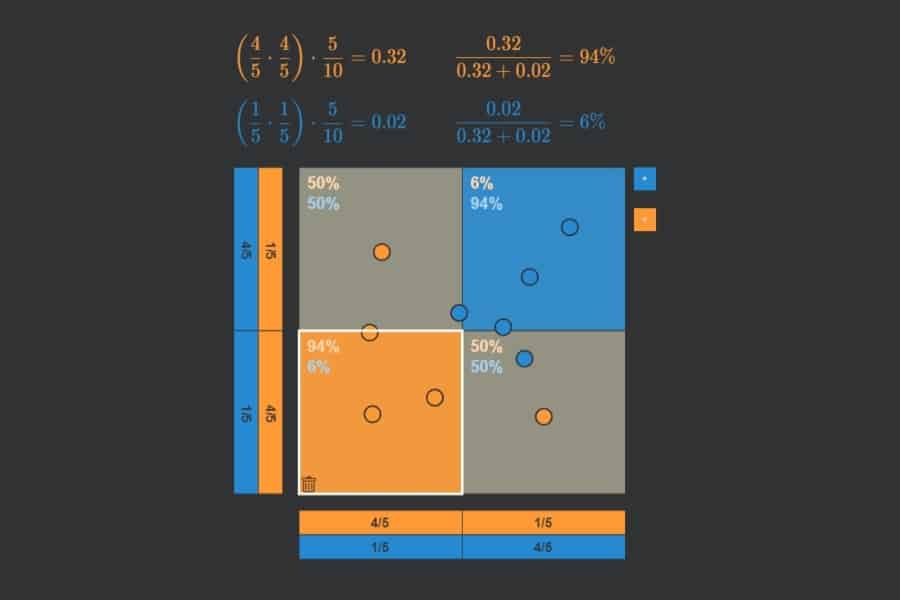
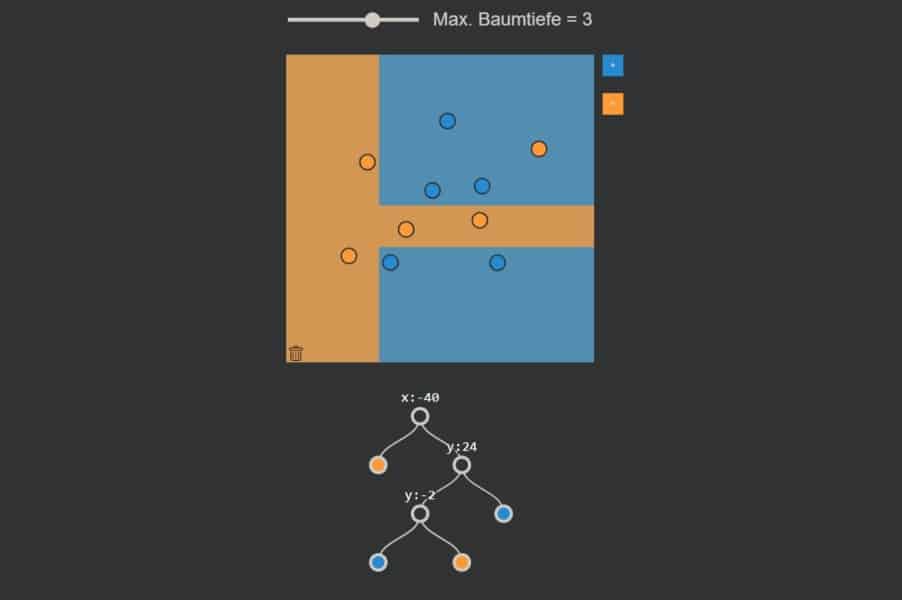
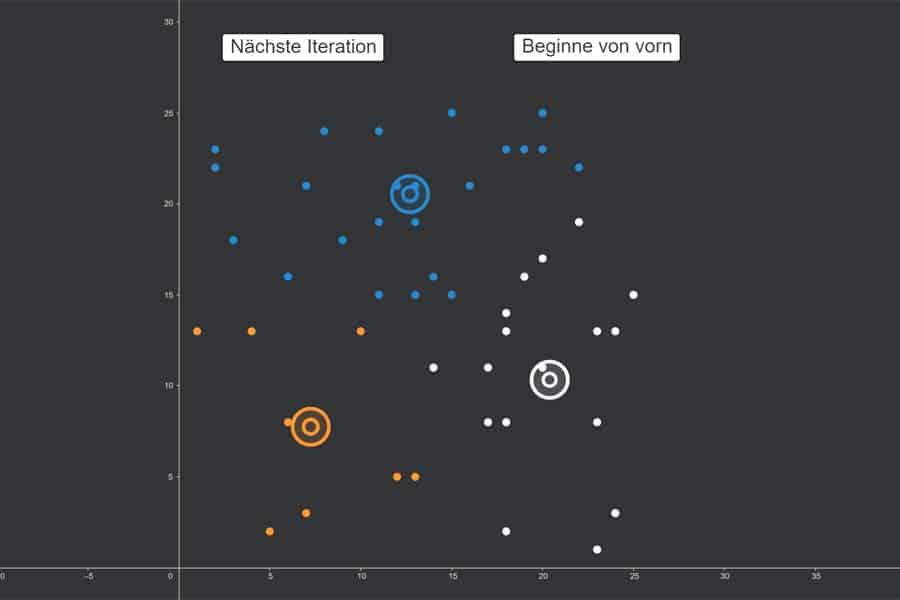
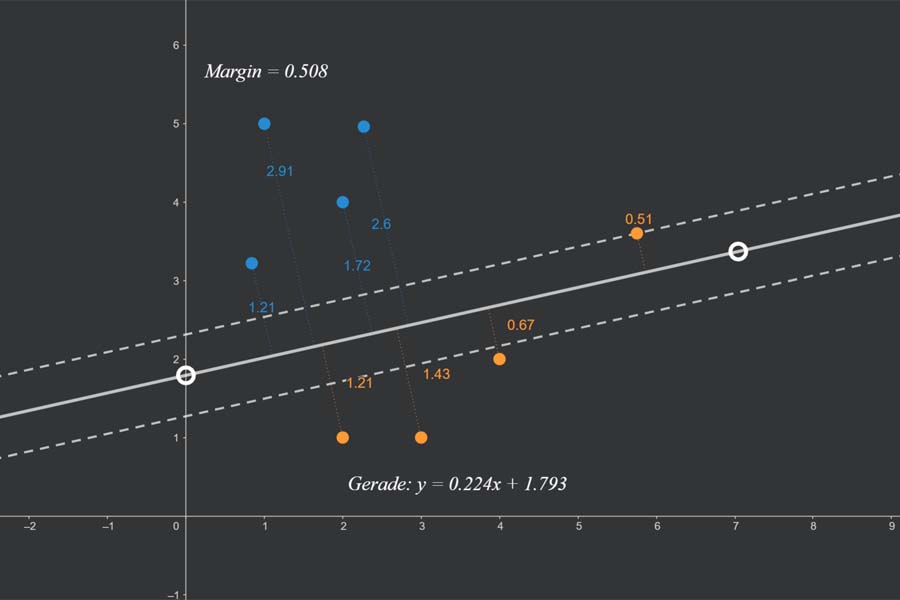
kNN-Algorithmus: Was wird blau, was orange?
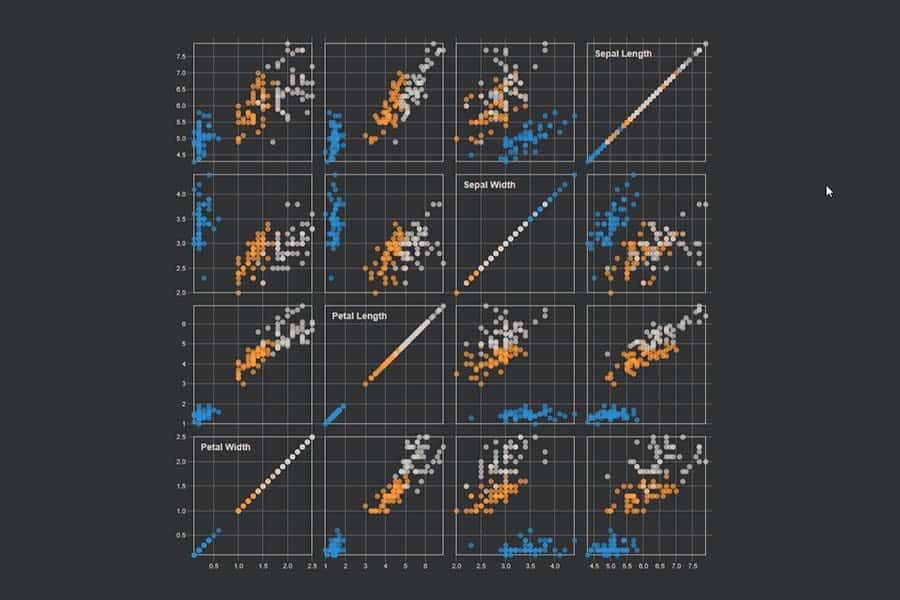
Wenn man sich mit Machine Learning befasst, kommt man an diesem Datensatz nicht vorbei: dem „Iris Flower Data Set“ des Biologen und Statistiker Ronald Fisher, welches dieser 1936 vorgestellt hat. Der Datensatz besteht aus jeweils 50 Beispielen dreier Iris-Arten (Iris setosa, Iris virginica and Iris versicolor). Für jede der 150 Blumen sind – neben ihrer Art – vier Merkmale erhoben: Länge und Breite der Blütenblätter (petal length, petal width) sowie Länge und Breite der Kelchblätter (sepal length, sepal width).
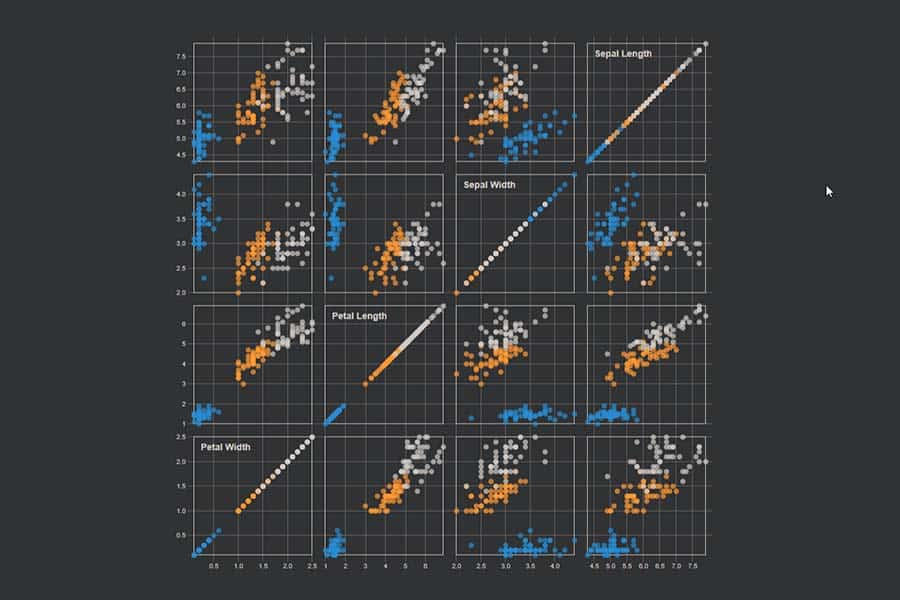
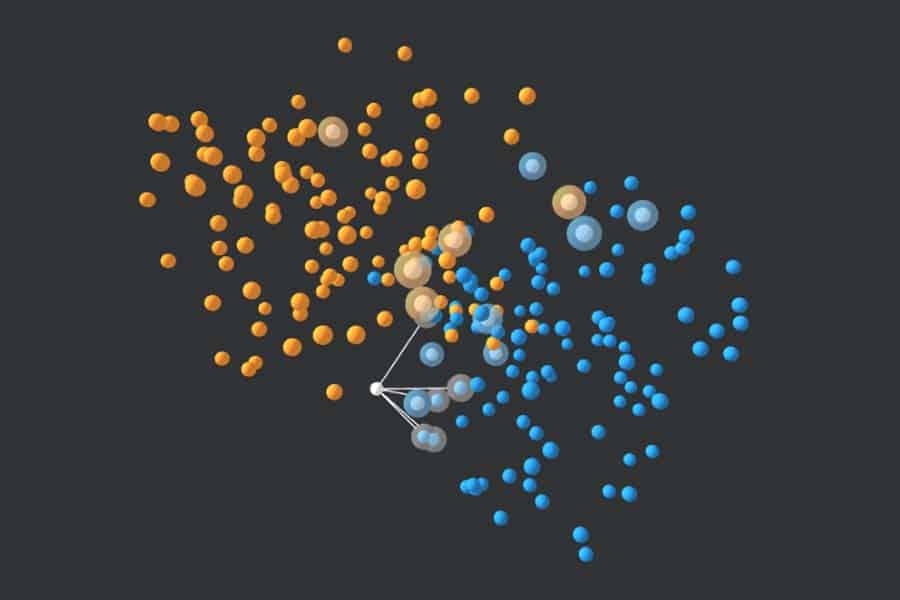
Der Datensatz wird oft in Form einer Scatter-Matrix dargestellt, in der jedes der vier Merkmale mit jedem anderen paarweise in einer zweidimensionalen Punktwolke dargestellt wird. Die drei verschiedenen Iris-Arten sind dabei farbig codiert.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
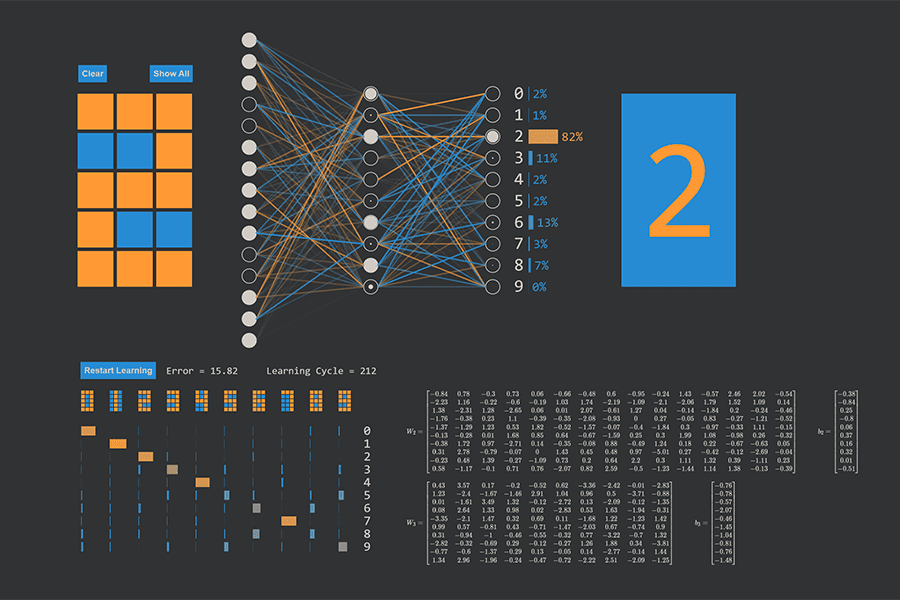
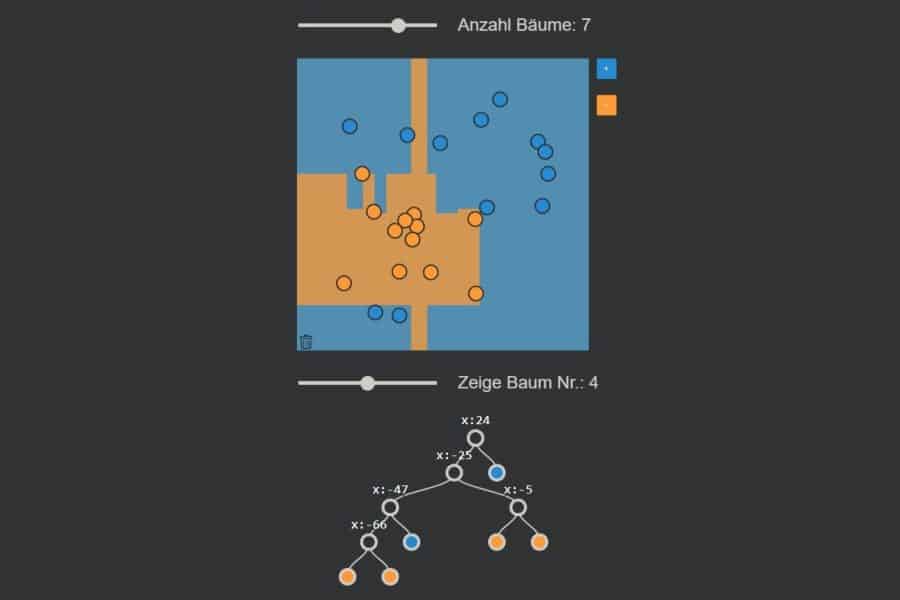
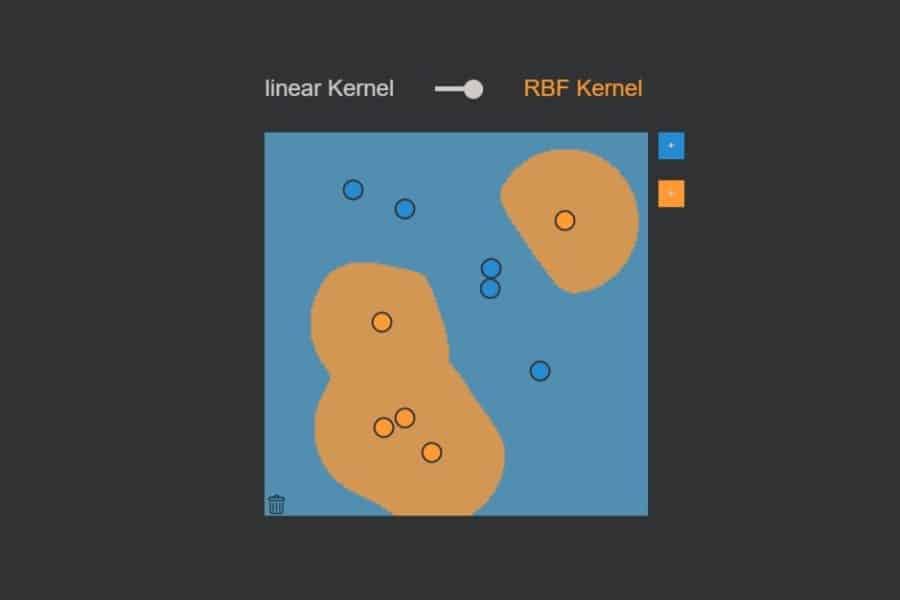
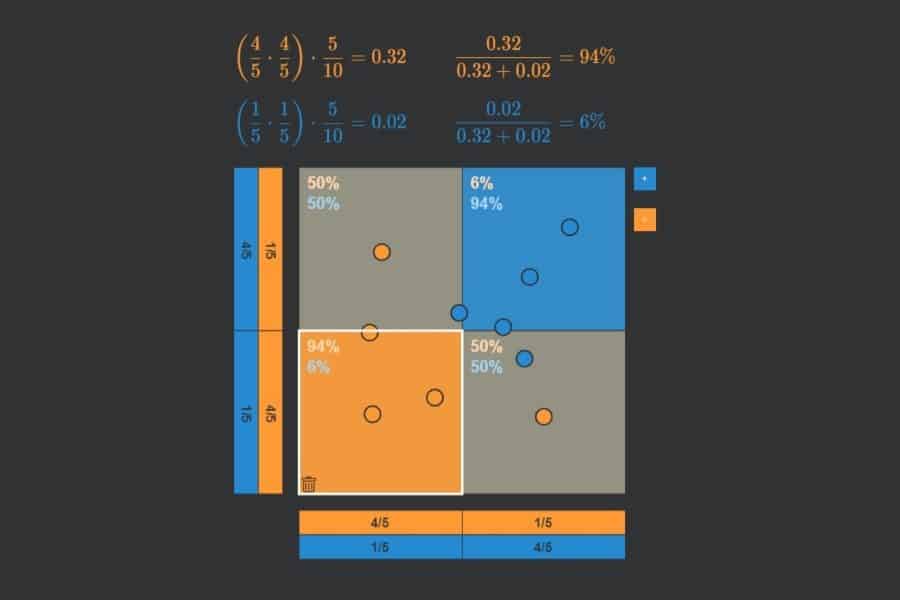
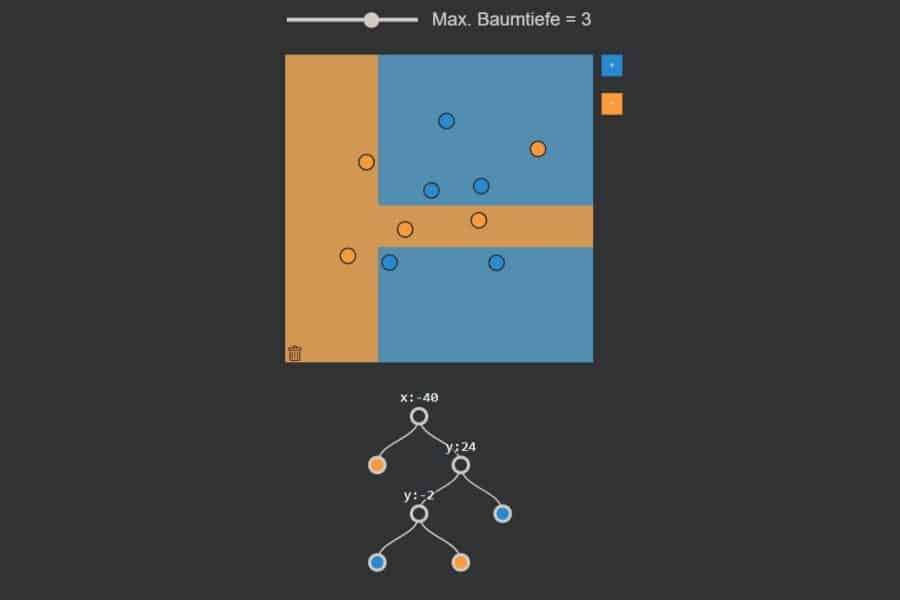
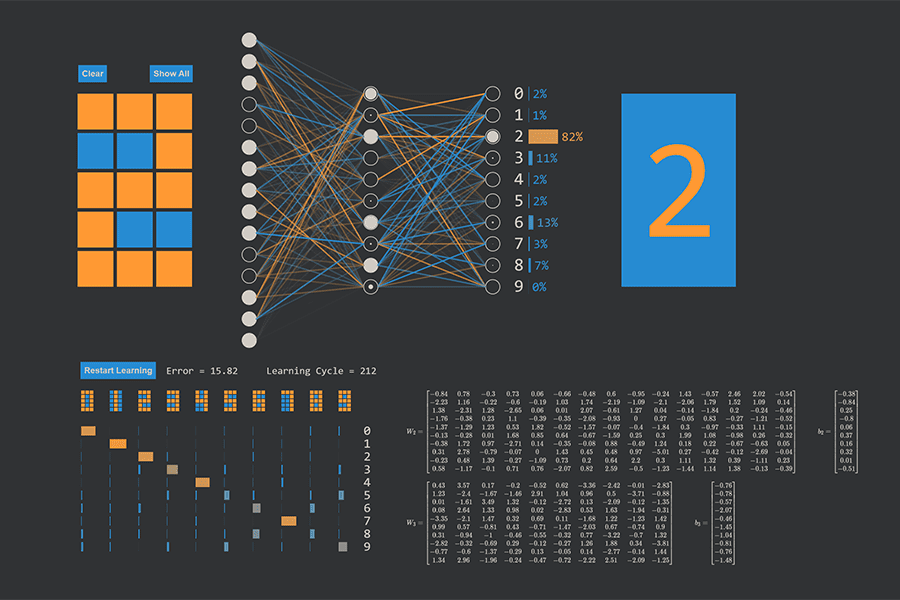
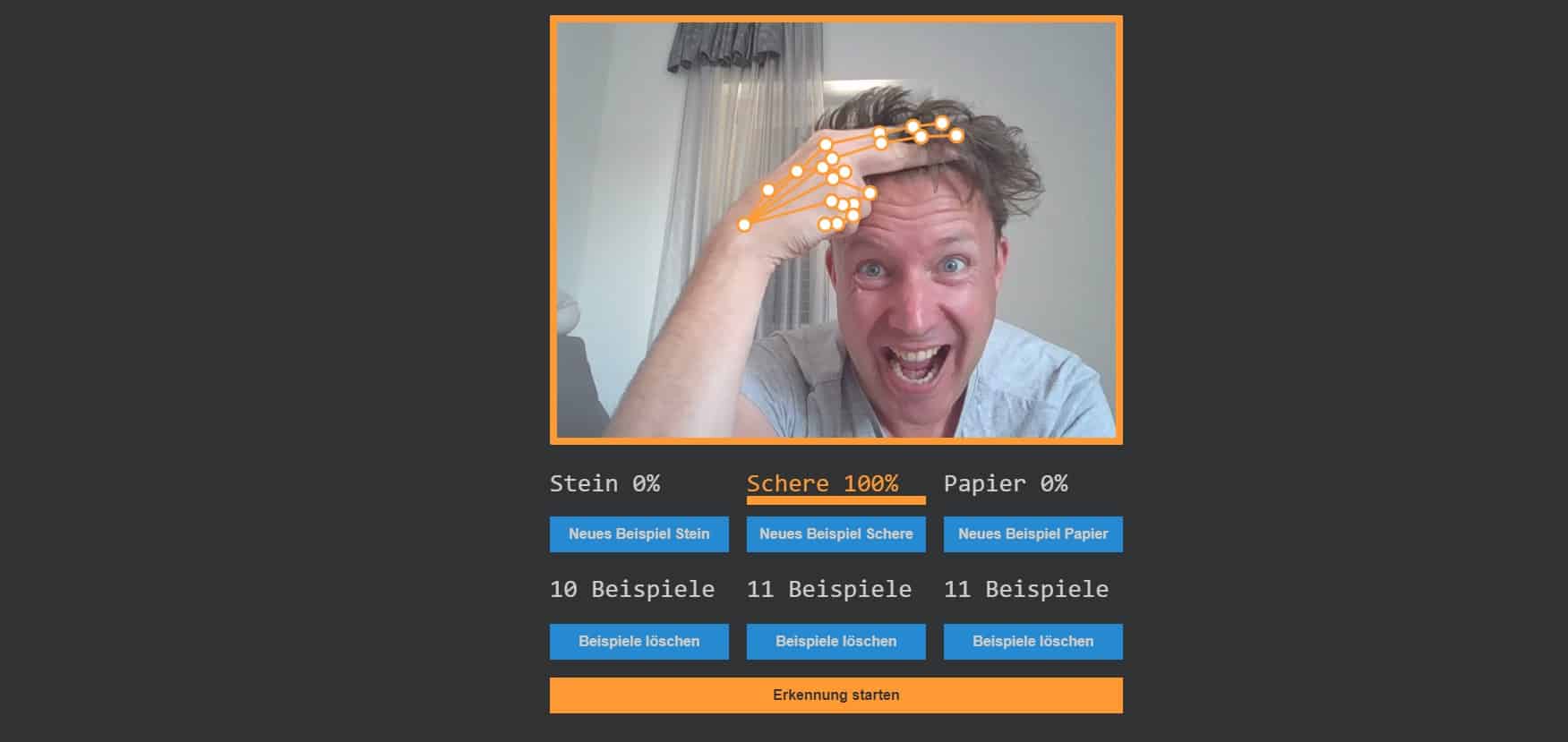
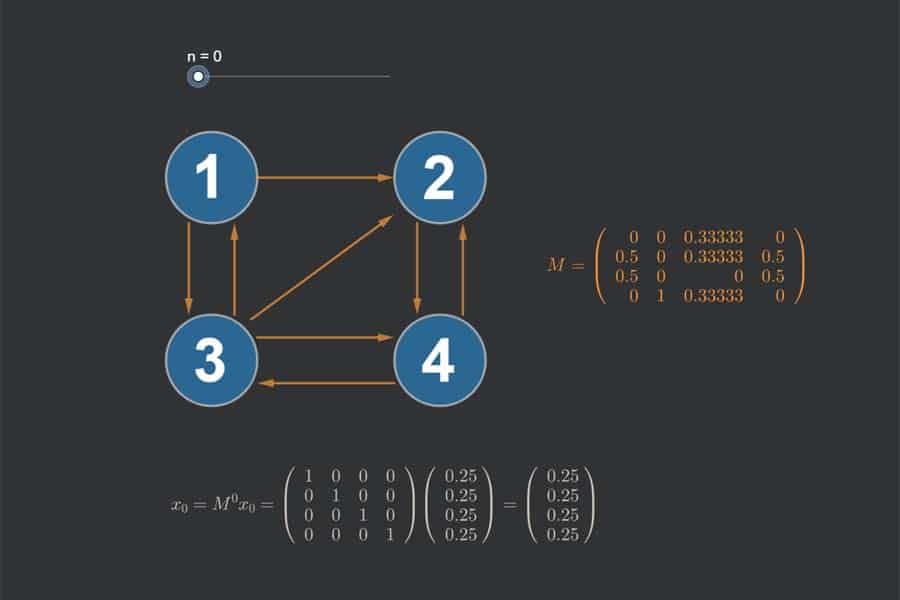
Interaktiv: K-Nearest-Neighbours-Algorithmus in Aktion