

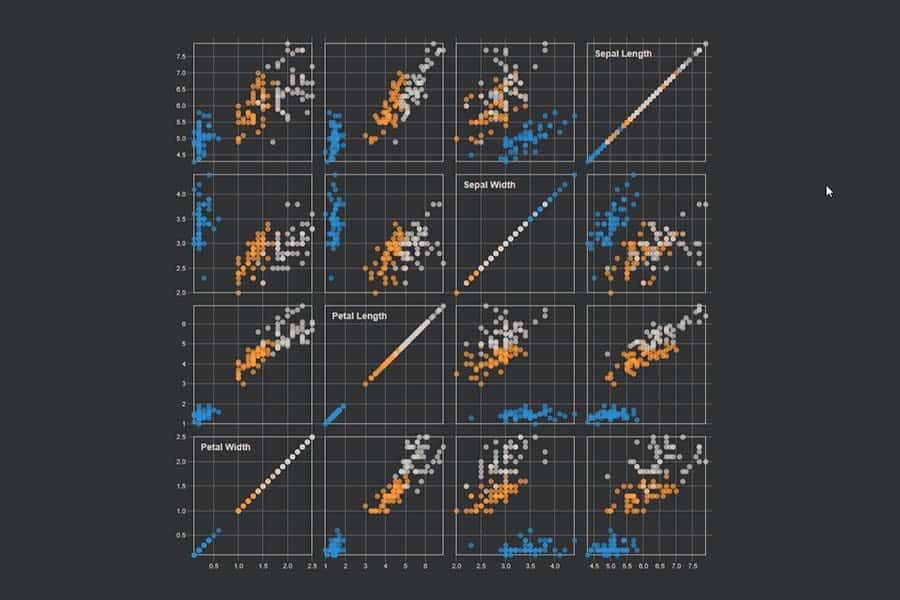
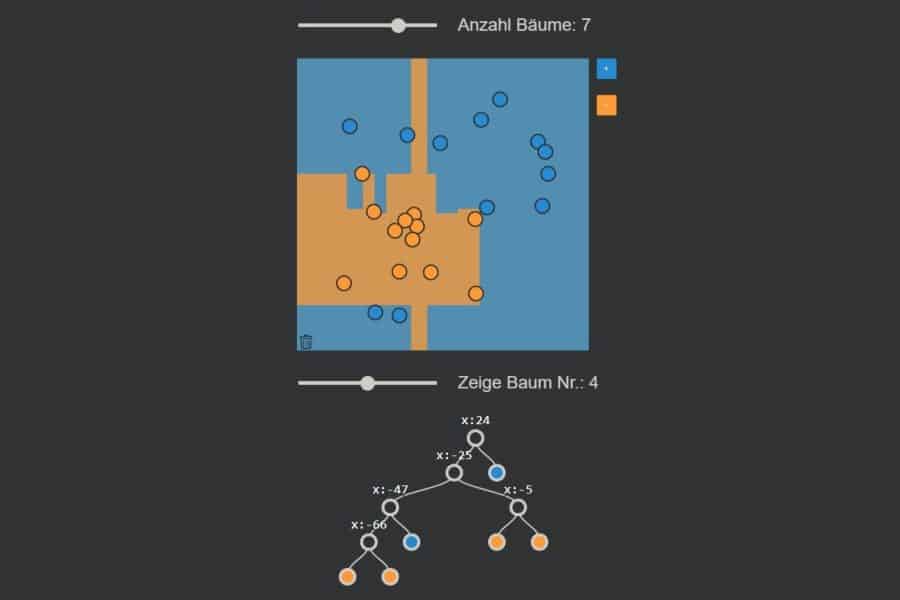
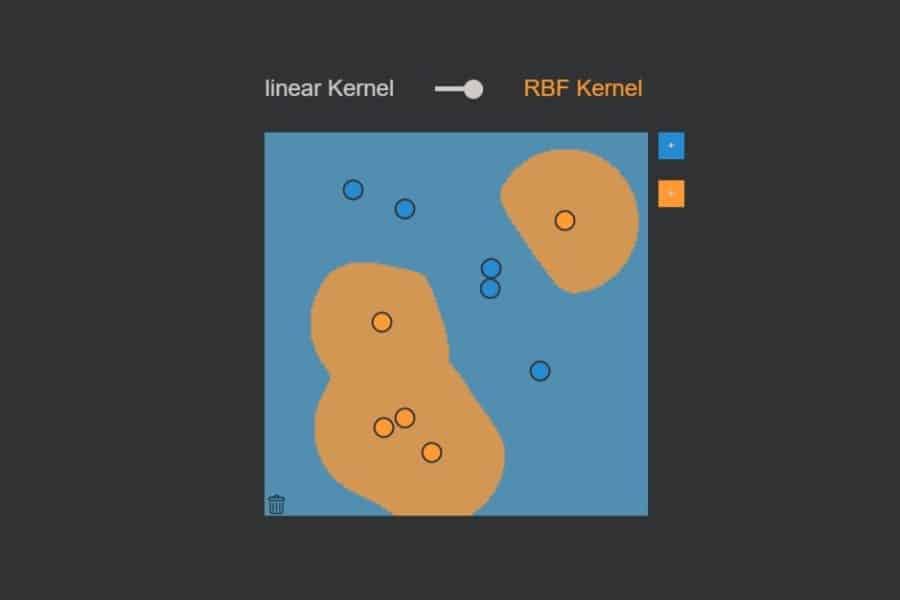
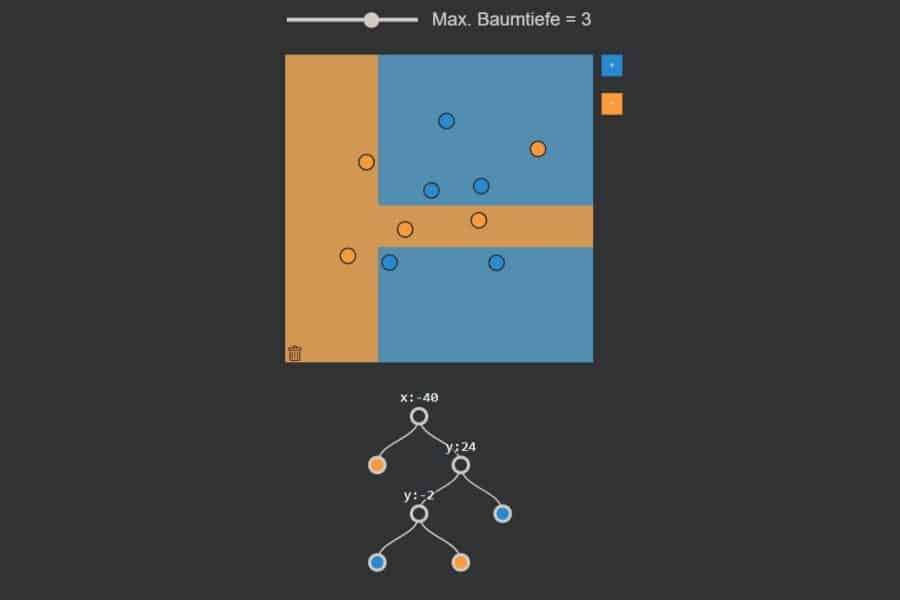
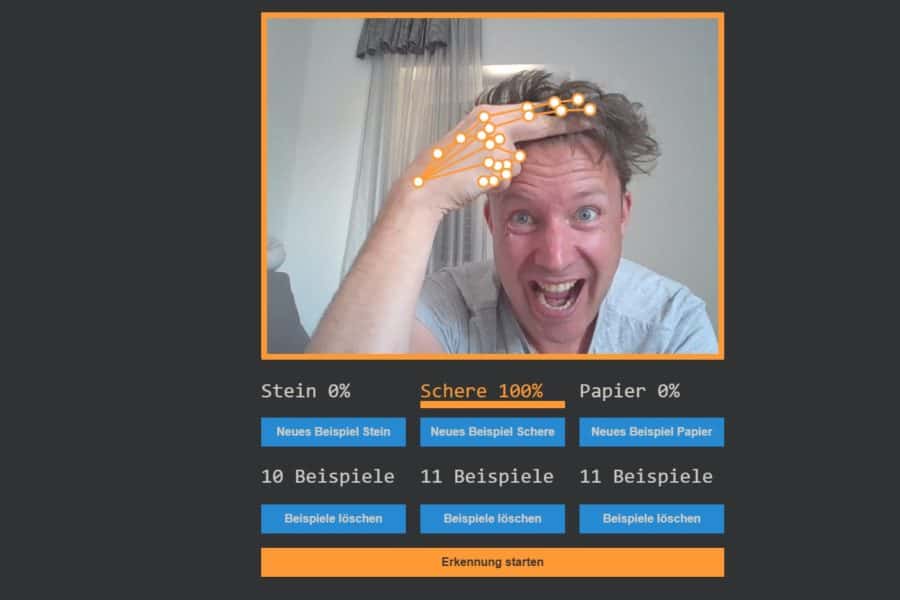
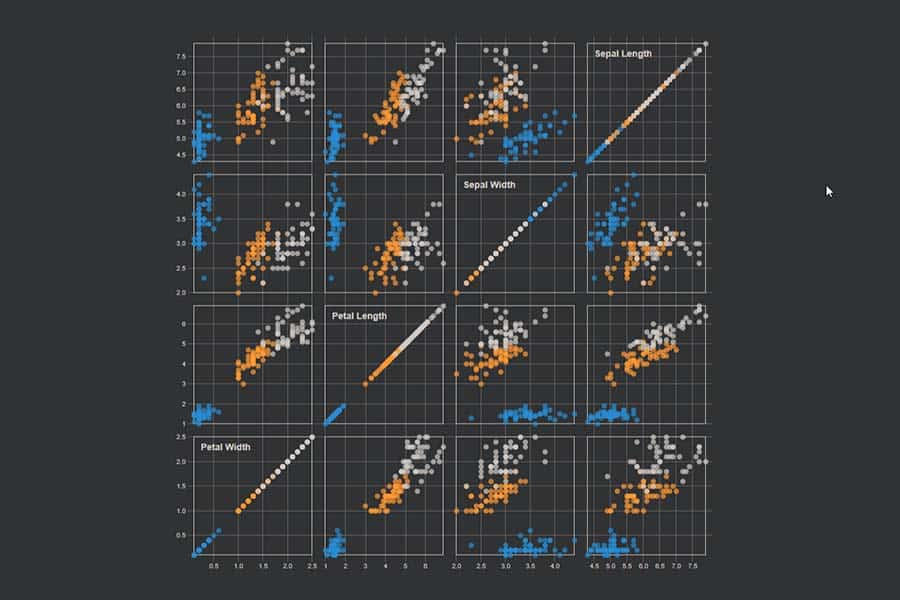
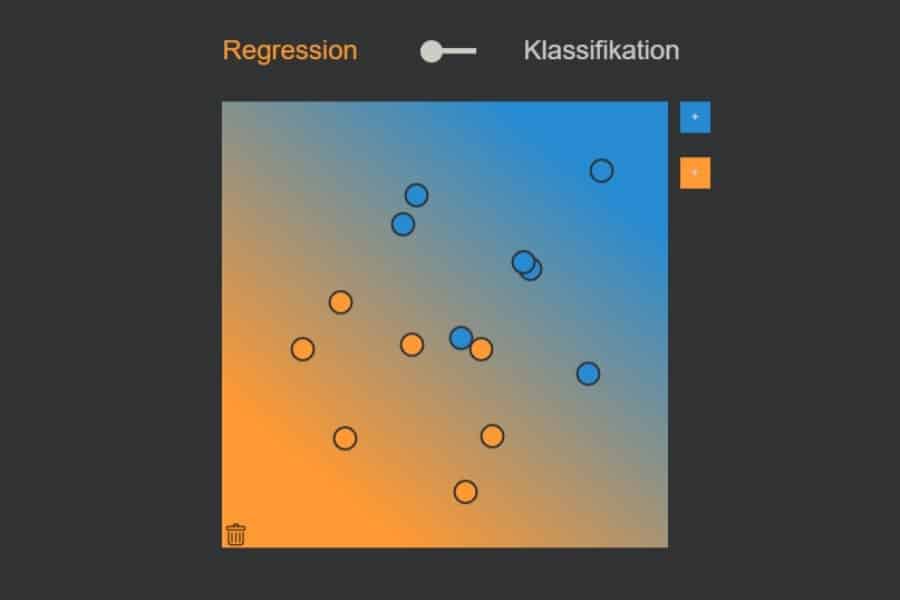
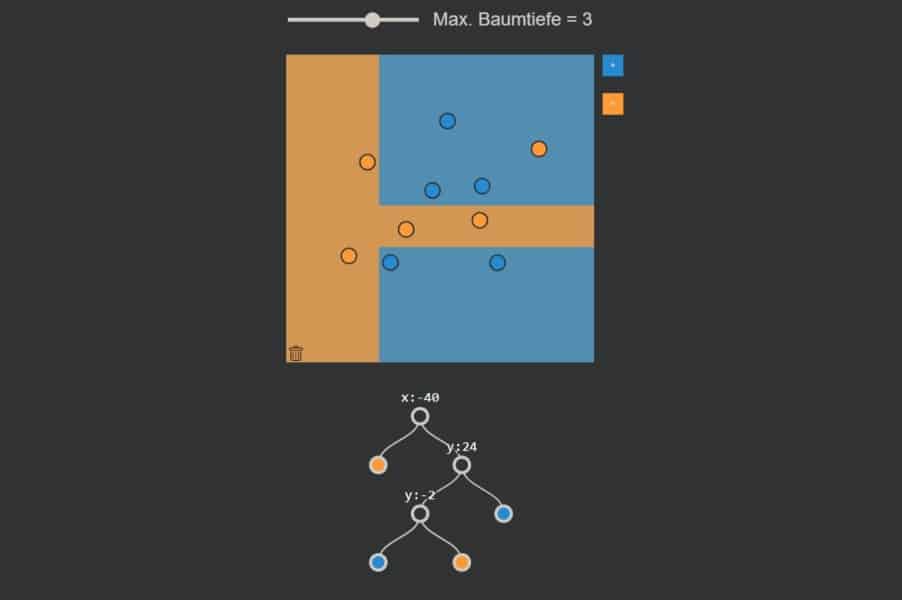
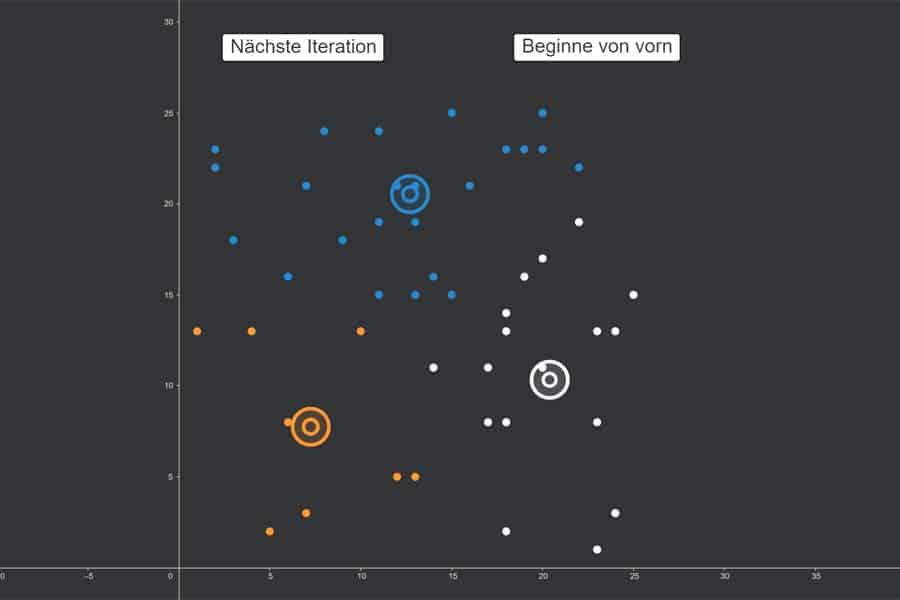
kNN-Algorithmus: Was wird blau, was orange?
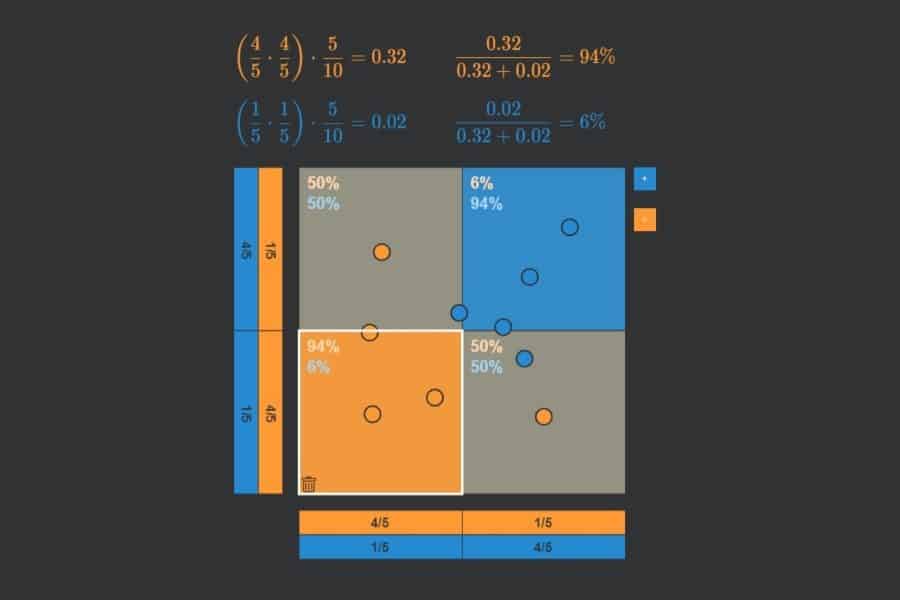
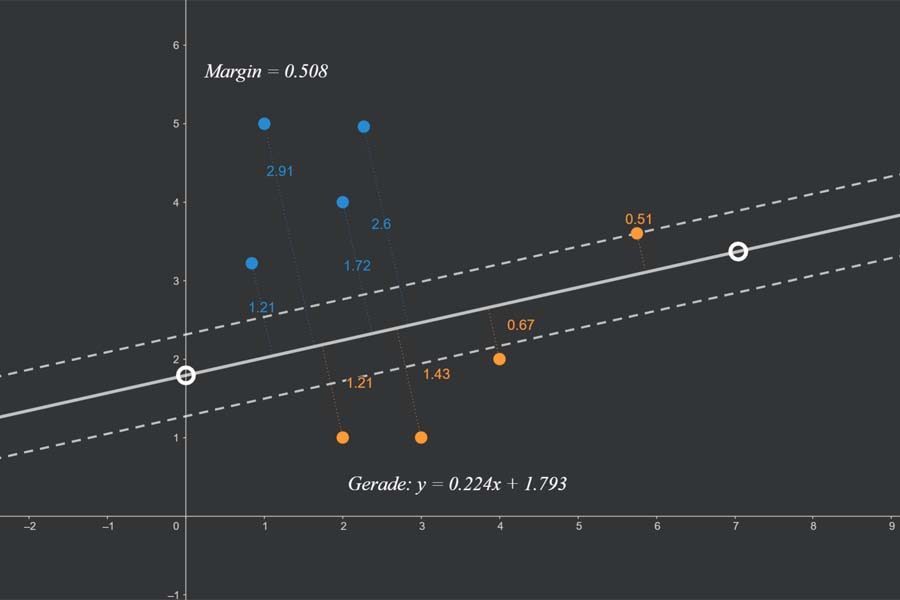
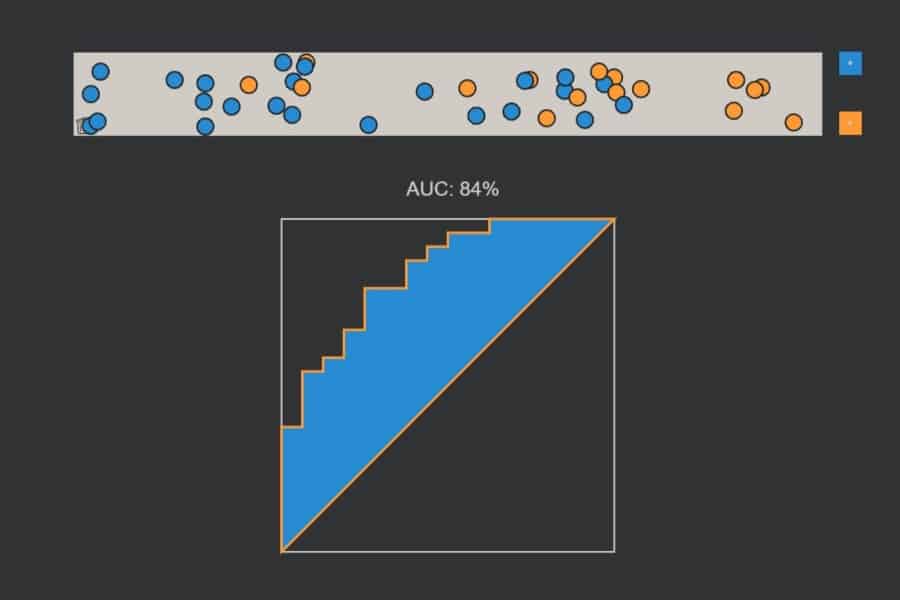
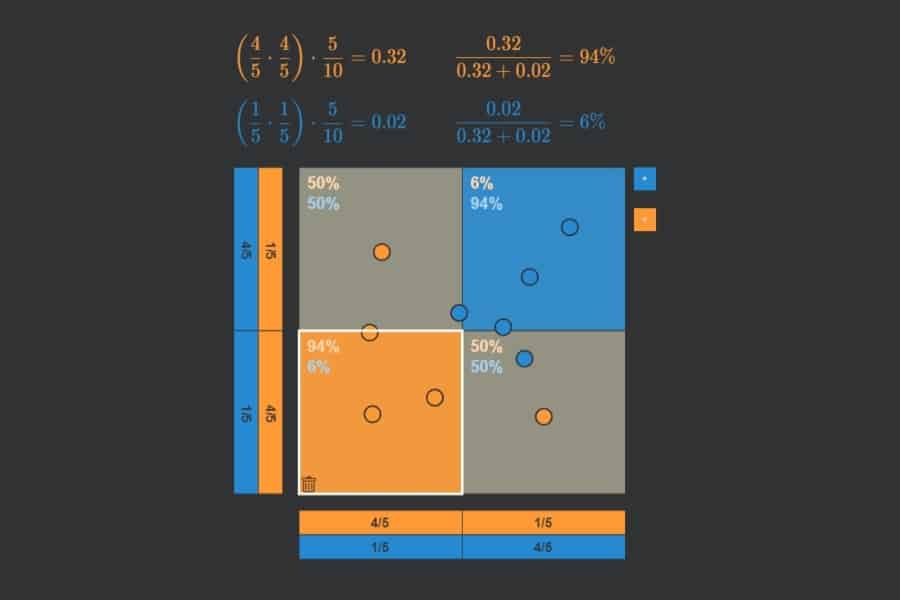
Die „ROC-Kurve“ (ROC = Receiver Operating Characteristic) dient zur Messung der Leistungsfähigkeit eines maschinellen Lernverfahrens bzw. eines jeden Prognoseverfahrens, welches Dinge in zwei Klassen A und B (z. B. blau und orange) einteilt. Die Idee beruht darauf, dass das Verfahren einen kontinuierlichen Output-Wert ausgibt, wobei alle Output-Werte unterhalb eines Schwellenwertes als A (blau) und ansonsten als B (orange) betrachtet werden. Das Verfahren ist dann umso leistungsfähiger, je mehr Punkte eines Testdatensatzes mit bekannten Klassen (blaue und orangefarbene Punkte) korrekt klassifiziert werden. Was nichts anderes bedeutet als: die Output-Werte für die blauen Punkte sollten am besten alle unterhalb und die der orangefarbenen oberhalb des Schwellenwertes liegen.
Sortiert man also alle Punkte des Testdatensatzes von links nach rechts nach aufsteigendem Output-Wert, dann sollten idealerweise alle blauen links und alle orangefarbenen rechts liegen. Nun kann ich für jeden möglichen Schwellenwert fragen, wie viel Prozent der blauen Punkte links von ihm korrekterweise als blau (True Positive Rate oder Sensitivität) und wie viel Prozent der orangefarbenen Punkte links von ihm fälschlicher als blau (False Positive Rate oder Spezifität) eingestuft werden. Diese beiden Zahlen kann ich als x- bzw. y-Koordinate eines Punktes nehmen und in ein Quadrat der Seitenlänge 1 (= 100%) zeichnen. Wenn ich dies für jeden möglichen Schwellenwert mache, dann setzen sich diese Punkt zu einer Kurve zusammen – die ROC-Kurve.
Je stärker die ROC-Kurve sich in den oberen linken Bereich des Quadrats erstreckt, desto besser die Performance des Verfahrens. Dies lässt sich in einer Zahl ausdrücken: der Fläche unter der Kurve (Area Under Curve – AUC).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
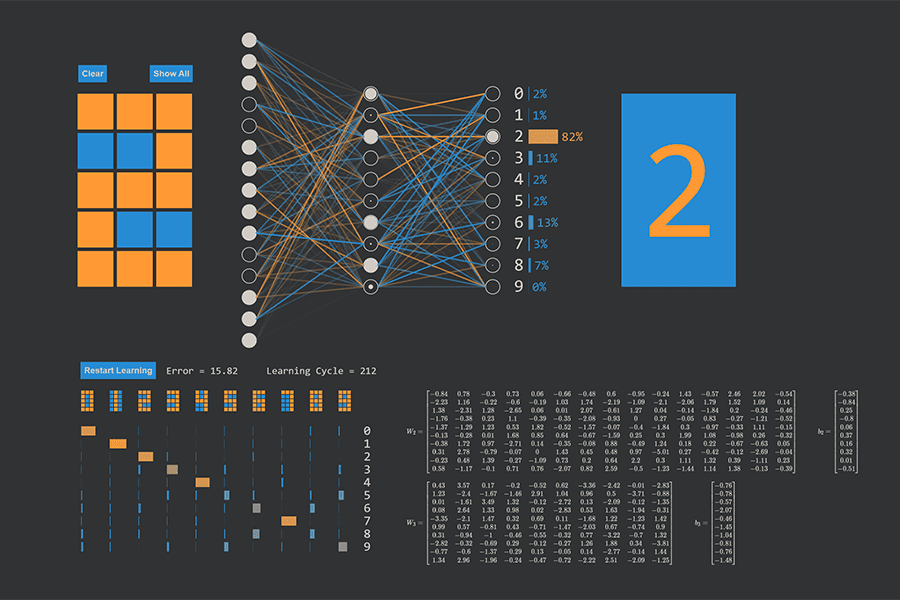
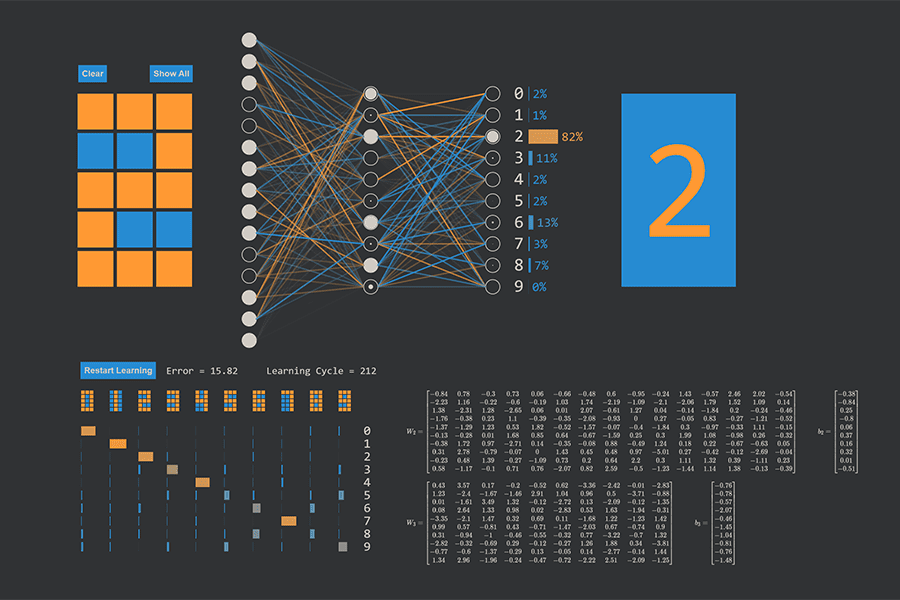
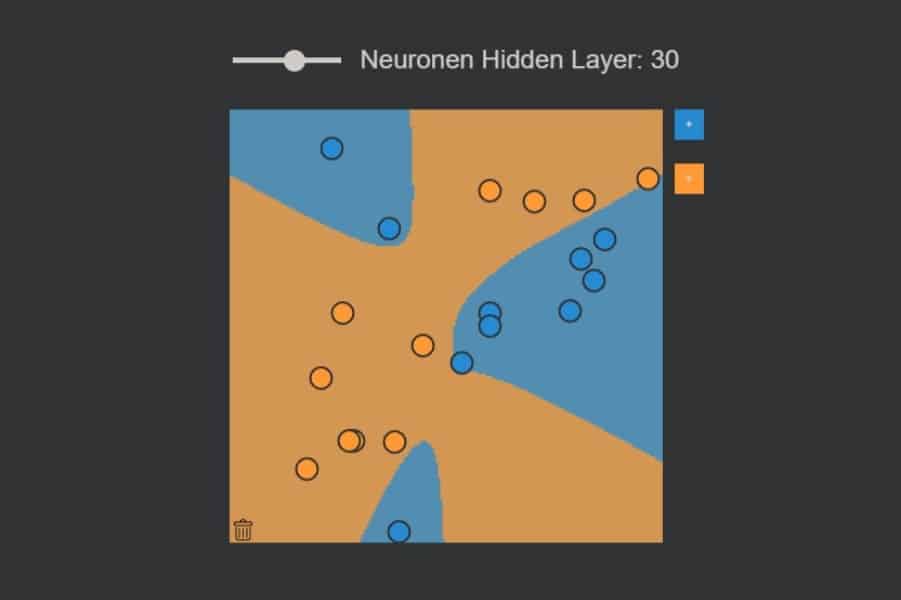
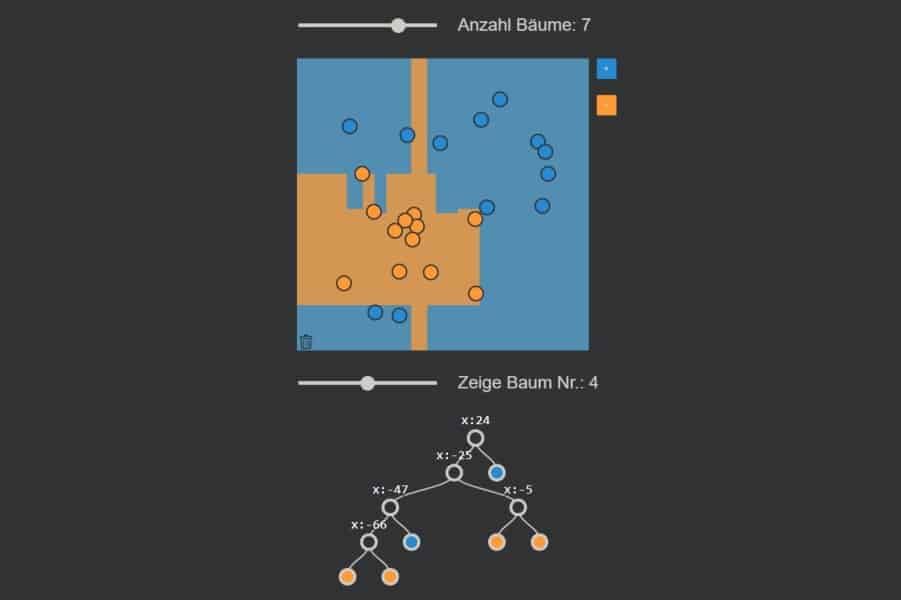
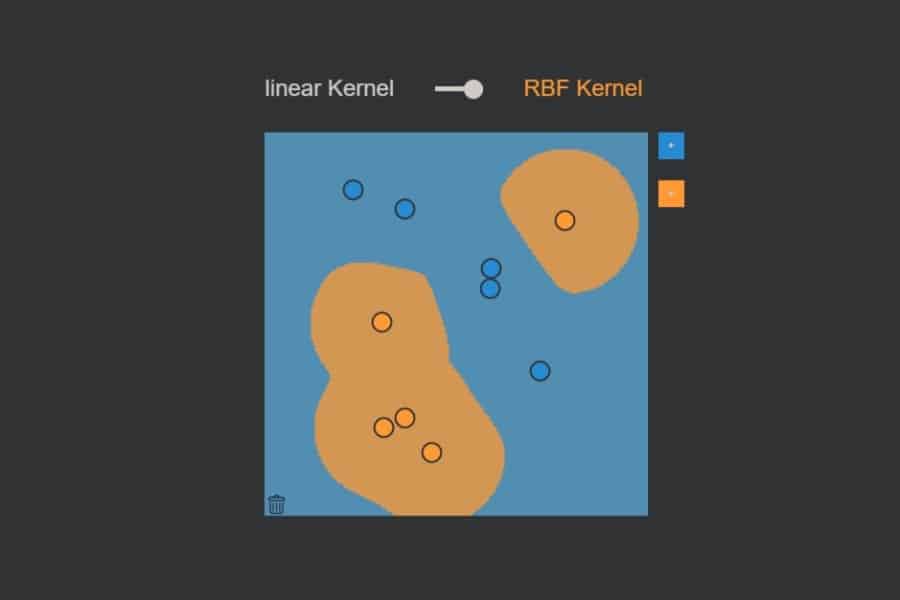
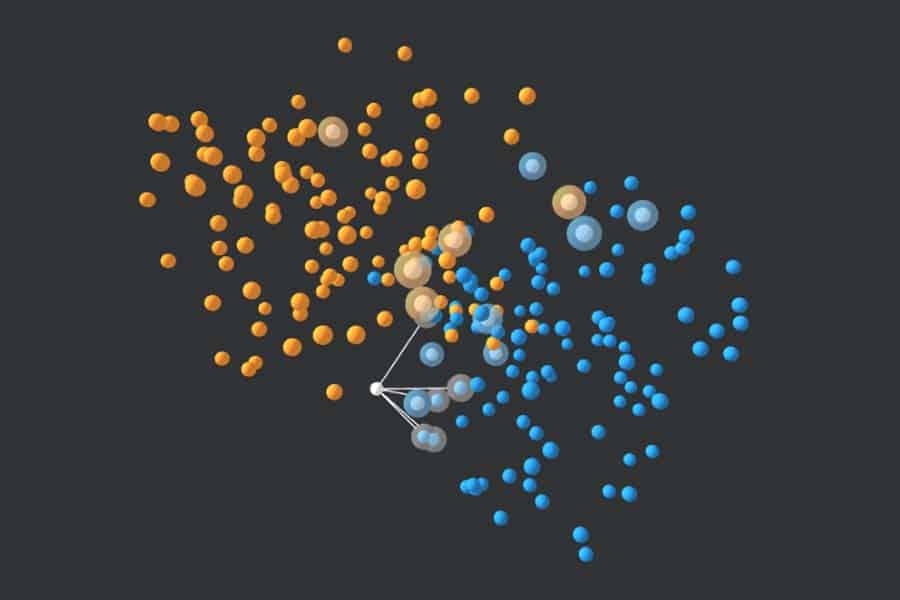
Interaktiv: K-Nearest-Neighbours-Algorithmus in Aktion